網頁內容抓取節點
網頁內容抓取節點能幫你輕鬆獲取網頁中的核心內容。它會智能識別並提取有價值的信息,自動過濾廣告、導航欄等干擾內容,讓你專注於真正需要的部分。無論是新聞採集、數據分析還是內容聚合,都能顯著提升工作效率。
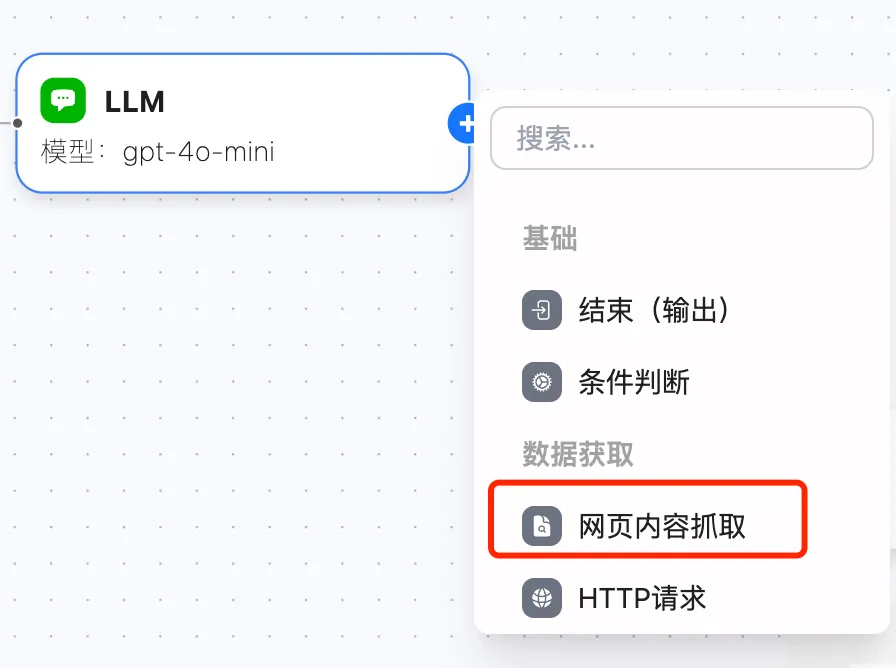
技術實現
我們採用了 Jina AI Reader 作為底層服務。這個專業的內容提取平臺具備以下能力:
-
智能識別
- 準確定位網頁主要內容
- 自動過濾廣告、導航等干擾項
- 轉換為清晰的Markdown文本
-
技術優勢
- 支持現代網頁技術
- 處理動態加載內容
- 針對不同網頁類型優化
節點配置
基礎設置
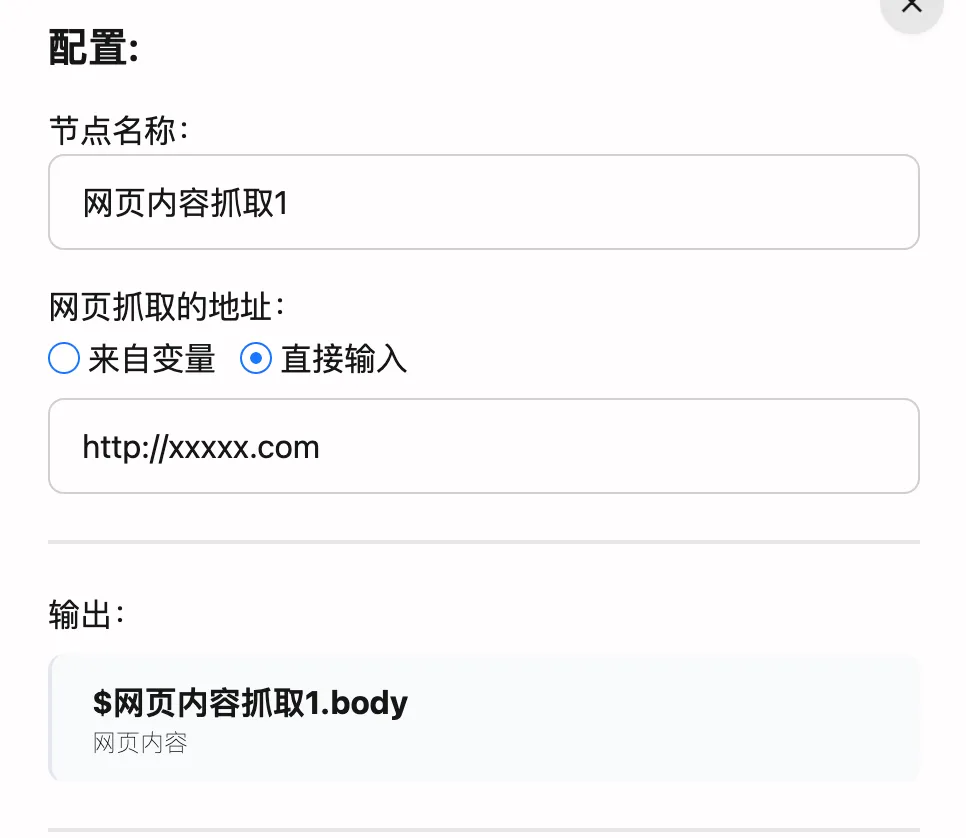
-
節點命名
- 設置一個好記的名字,比如”新聞抓取”、“文章採集”
- 其他節點會用這個名字引用內容
- 改名後引用方式也會相應改變
- 建議用能體現功能的名字,方便後期維護
-
網頁地址 兩種設置方式:
- 變量引用
- 從其他節點獲取網址
- 特別適合動態變化的網址
- 需要指定包含網址的變量
- 直接填寫
- 手動輸入固定網址
- 記得帶上
http://或https:// - 比如:
https://example.com/page
- 變量引用
輸出內容
節點會輸出以下內容:
- 通過
$節點名稱.body獲取 - 內容已轉為Markdown格式
- 保留了文章的核心信息
- 便於後續處理和分析
實際應用
LLM新聞總結與數據分析
[網頁抓取] --------> [LLM分析] --------> [輸出摘要] | | | | | | 獲取新聞原文 理解內容 輸出LLM書寫的摘要把它用在新聞總結上,可以:
- 自動抓取多個新聞源,構建新聞監測系統
- 用LLM理解新聞重點,進行情感分析
- 生成簡明扼要的摘要,支持多語言
- 提取關鍵事實和觀點,構建知識圖譜
- 多維度分析新聞價值,支持數據可視化
使用技巧
網址處理
- 檢查網址格式是否完整
- 處理好特殊字符的編碼
- 確保網址能正常訪問
數據處理
- 配合LLM提取重要信息
- 用JSON節點處理結構化數據
- 及時保存處理結果
注意事項
推薦搭配
這些節點和網頁抓取很配:
-
LLM節點
- 分析網頁內容
- 生成內容摘要
- 提取關鍵信息
- 支持多語言處理
- 進行情感分析
-
JSON內容提取
- 解析數據結構
- 提取想要的字段
- 轉換數據格式
- 支持API對接
- 構建數據管道
和HTTP節點比較
雖然網頁內容抓取節點和HTTP節點都能訪問網頁,但各有特長:
網頁內容抓取節點的特點
- 專門提取有價值的內容
- 自動清理無用的元素
- 輸出整潔的Markdown文本
- 特別適合需要理解內容的場景
HTTP節點的特點
- 發送各類HTTP請求
- 獲取完整的響應body數據
- 保持原始的數據格式
- 適合API對接場景
怎麼選?
- 想讀懂網頁內容,就用網頁內容抓取節點
- 要調用接口拿數據,就用HTTP節點
定製服務
官方團隊為您量身定製專業的自動化解決方案