文本截斷節點
文本截斷節點用於將長文本裁剪為指定長度,支持按照字符或按照行進行截斷。當需要限制模型回覆、日誌內容或展示摘要時,它能在流程中發揮重要作用。
節點配置
基礎設置
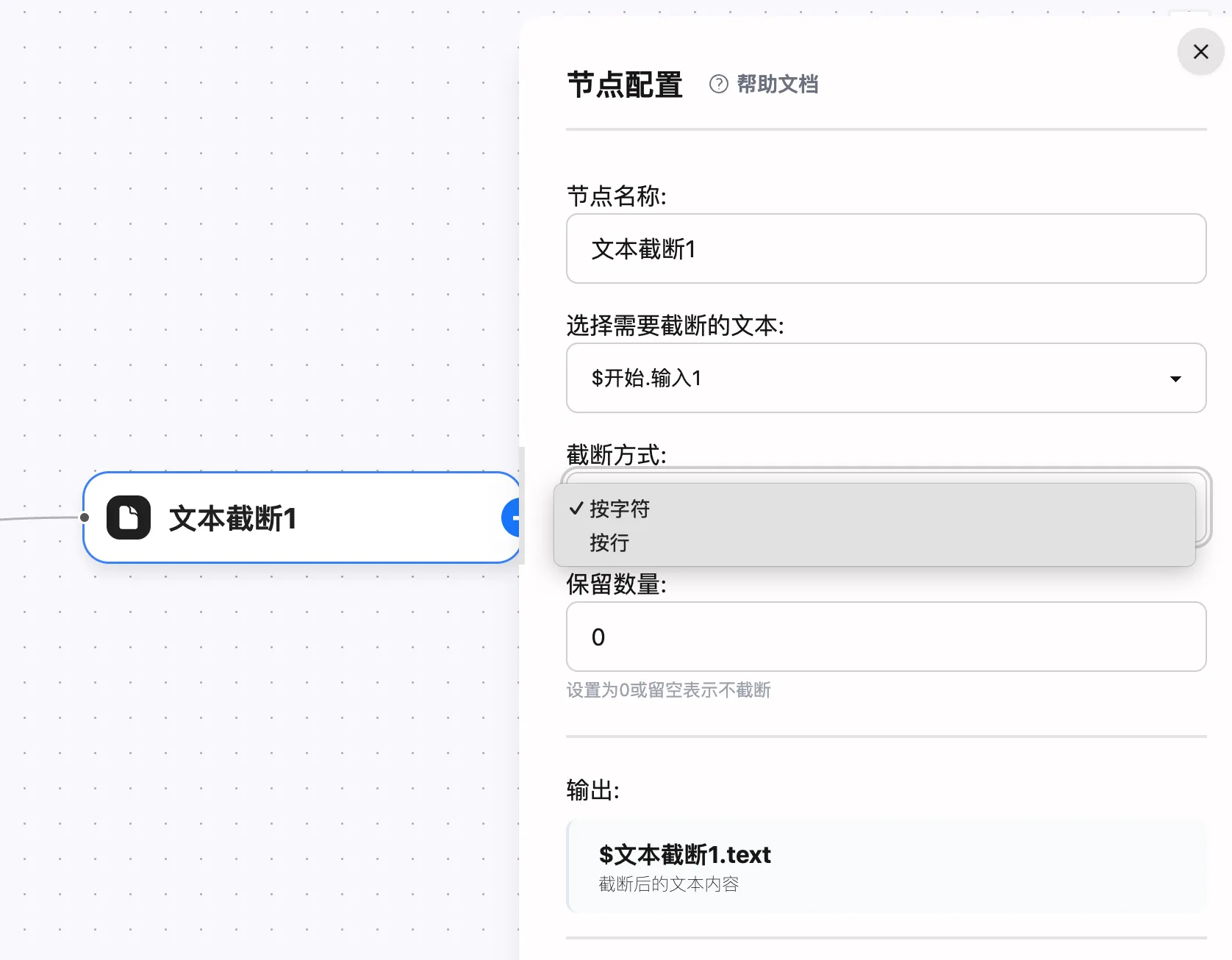
-
節點名稱
- 建議使用“動作 + 對象”的命名方式,如“截斷AI回覆”
- 輸出變量默認以節點名稱作為前綴,例如
$截斷AI回覆.text
-
文本來源
- 選擇來自上游節點的文本變量,例如
$LLM.output、$輸入.content - 支持通過上下文變量引用任意字符串
- 選擇來自上游節點的文本變量,例如
-
截斷方式
- 按字符(默認):基於 Unicode 字符數量裁剪,適合控制總長度
- 按行:以換行符
\n分割後截取前 N 行,適合日誌、表格類內容
-
保留數量
- 填入正整數或 0
- 當值為 0 時,輸出為空字符串
- 字段必須填寫且為非負數,支持上下文變量替換(例如
$設置.limit)
-
輸出變量
- 默認輸出鍵為
text - 在後續節點中通過
$節點名稱.text引用截斷結果
- 默認輸出鍵為
工作原理
- 節點執行時,會先解析所有輸入字段中的
$節點.字段佔位符,支持嵌套路徑。 - 若“保留數量”為空或非數字,系統會拋出錯誤,終止當前工作流,以避免不明確的輸出。
- 截斷邏輯如下:
- 按字符:會按照 Unicode 字符數量裁剪,支持emoji、中文等多字節字符。
- 按行:使用換行符
\n分割,僅截取前 N 行並保持原有換行。
- 截斷完成後,節點會把結果寫入上下文,可在調試中查看
$節點名稱.text。
使用示例
1. 控制模型回覆長度(按字符)
- 在 LLM 節點之後添加“文本截斷”節點。
- 配置:
文本:$LLM.output截斷方式:按字符保留數量:280
- 將
$文本截斷.text傳遞給內容拼接器或輸出節點,即可確保回覆不超過 280 個字符。
2. 提取日誌前幾行(按行)
- 輸入節點或 HTTP 節點獲取多行日誌。
- 配置文本截斷節點:
文本:$日誌抓取.response截斷方式:按行保留數量:5
- 在輸出節點中引用
$文本截斷.text,僅呈現日誌的前 5 行。
高級用法
- 動態限制:通過變量控制保留數量,例如
$配置.maxChars,實現按環境動態調整限制。 - 串聯使用:先按行截斷,再按字符精修,確保文本既保留結構又滿足最終長度需求。
- 錯誤兜底: 在截斷後結合條件節點,當輸出為空時給出默認提示,避免下游節點收到空內容。
最佳實踐
- 事先評估長度:使用內容拼接器或調試功能,確認原始文本長度與期望值的關係。
- 明確單位:團隊協作時註明是“按字符”還是“按行”,防止誤解。
- 合理拆分:極長文本推薦先使用其他節點(如 JSON 處理或代碼執行)預處理,再進行截斷。
- 保持冪等:對於可能重複執行的流程,確保截斷後的結果可重複使用而不會造成信息丟失。
常見問題
定製服務
官方團隊為您量身定製專業的自動化解決方案