LLM節點
LLM節點是FlowAI智能工作流中用於與大語言模型進行交互的核心組件。通過LLM節點,您可以實現智能對話、文本分析、內容生成等多樣化的AI應用場景。
LLM節點基礎配置
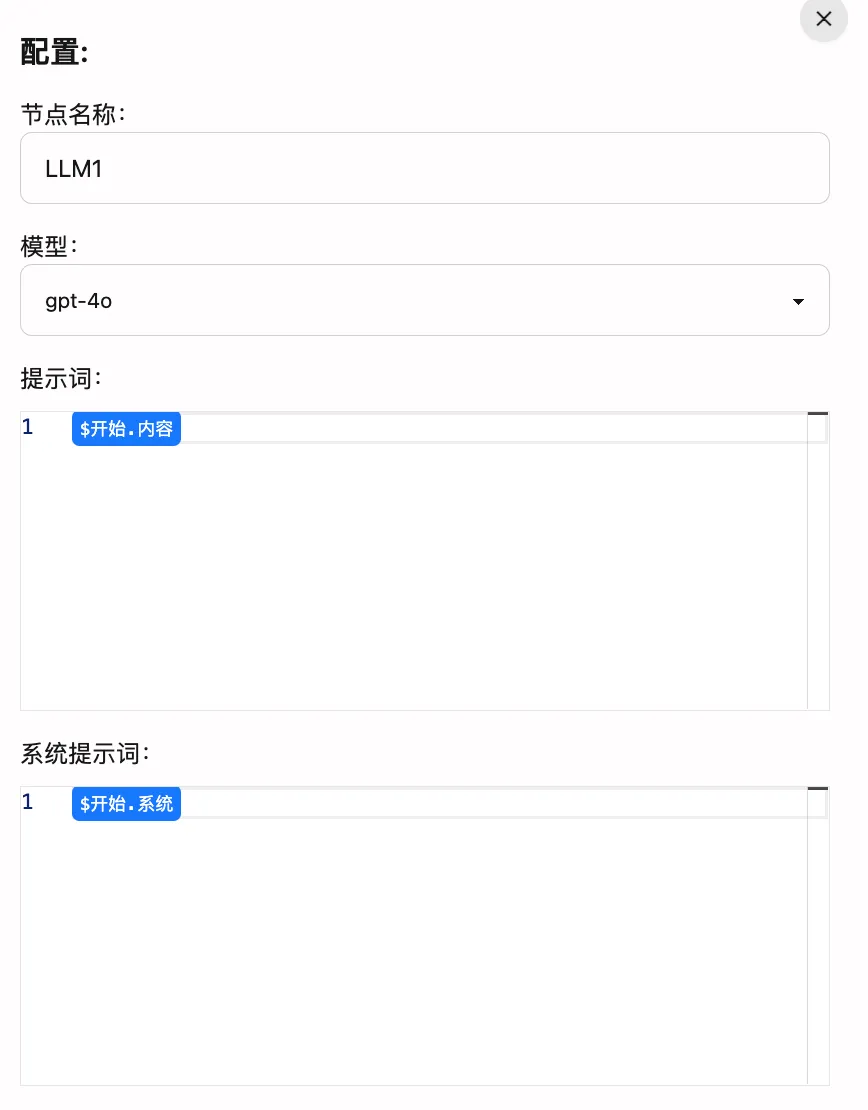
節點屬性詳解
-
節點名稱:可自定義的LLM節點標識。修改後會影響工作流中其他節點對該節點的引用。例如,將”LLM1”改為”GPT4”後,其他節點的引用將從
$LLM1.result變為$GPT4.result。建議使用有意義的名稱,以便於理解和維護。 -
模型:通過下拉菜單選擇要使用的語言模型。目前支持:
- GPT-4o:性能與成本的良好平衡
- GPT-4o-mini:性能與成本的平衡
- 其他模型:根據實際需求選擇
-
提示詞編輯區:用於編寫發送給語言模型的提示詞(Prompt)。您可以:
- 使用變量語法引用其他節點的輸出
- 編寫多行提示詞
- 設置格式化要求
-
系統提示詞:用於設置模型的工作模式,例如:
- 要求模型輸出JSON格式
- 要求模型輸出特定格式的文本
- 要求模型輸出特定主題/風格的文本
模型選擇與對比
提示詞編寫技巧
提示詞是與語言模型交互的關鍵。好的提示詞可以顯著提升模型輸出的質量。以下是一些編寫技巧:
基礎語法
我是 $開始.用戶名,請為我生成一個個性化的問候語。結構化輸出示例
請分析以下文本的情感傾向,並以JSON格式輸出:文本:$輸入.評論內容要求輸出格式:{ "sentiment": "正面/負面/中性", "confidence": 0-1之間的數值, "keywords": ["關鍵詞1", "關鍵詞2"]}角色設定示例
你現在是一位專業的文案編輯,請幫我修改以下文本,使其更加吸引人:$輸入.原始文案要求:1. 保持核心信息不變2. 增加感情色彩3. 使用更生動的描述高級配置詳解
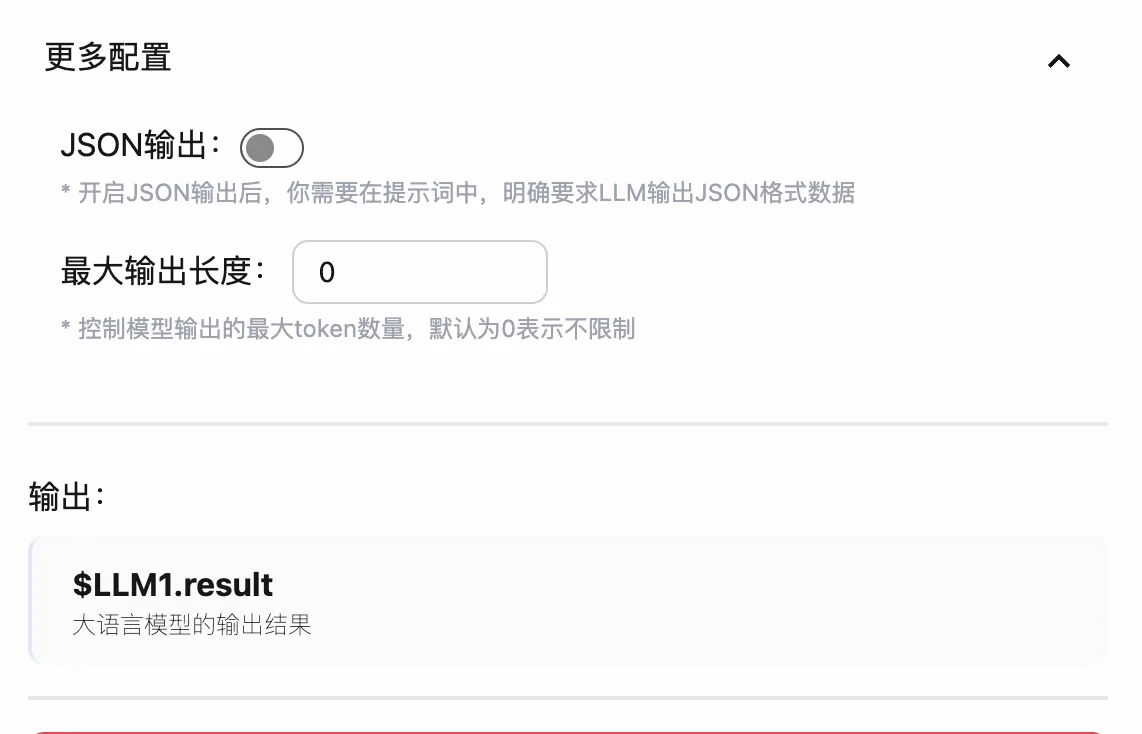
JSON輸出功能
在”更多配置”中,您可以啟用JSON輸出功能,這對於需要結構化數據處理的場景非常有用:
-
使用場景:
- 數據分析和處理
- API接口對接
- 多輪對話狀態管理
- 結構化信息提取
-
最佳實踐:
- 在提示詞中明確指定JSON結構,如果不指定,模型API會返回失敗。
- 使用示例說明每個字段的格式
- 處理可能的異常情況
-
示例提示詞:
請將以下文本轉換為JSON格式:標題:$輸入.標題內容:$輸入.內容要求輸出格式:{ "title": "文章標題", "summary": "200字以內的摘要", "keywords": ["關鍵詞1", "關鍵詞2", "關鍵詞3"], "category": "文章分類", "readingTime": "預計閱讀時間(分鐘)"}最大輸出長度控制
合理設置最大輸出長度可以優化性能和成本:
-
參數說明:
- 0:不限制輸出長度
- 正整數:限制最大token數量
-
設置建議:
- 短文本生成:500-1000 tokens
- 一般對話:1000-2000 tokens
- 長文本生成:2000-4000 tokens
- 特殊需求:根據實際情況調整
-
注意事項:
- token數量與實際字數不完全對應
- 中文字符通常消耗更多tokens
- 保留足夠餘量避免內容截斷
節點輸出使用
LLM節點的輸出通過 $LLM節點名稱.result 訪問,例如: $LLM1.result
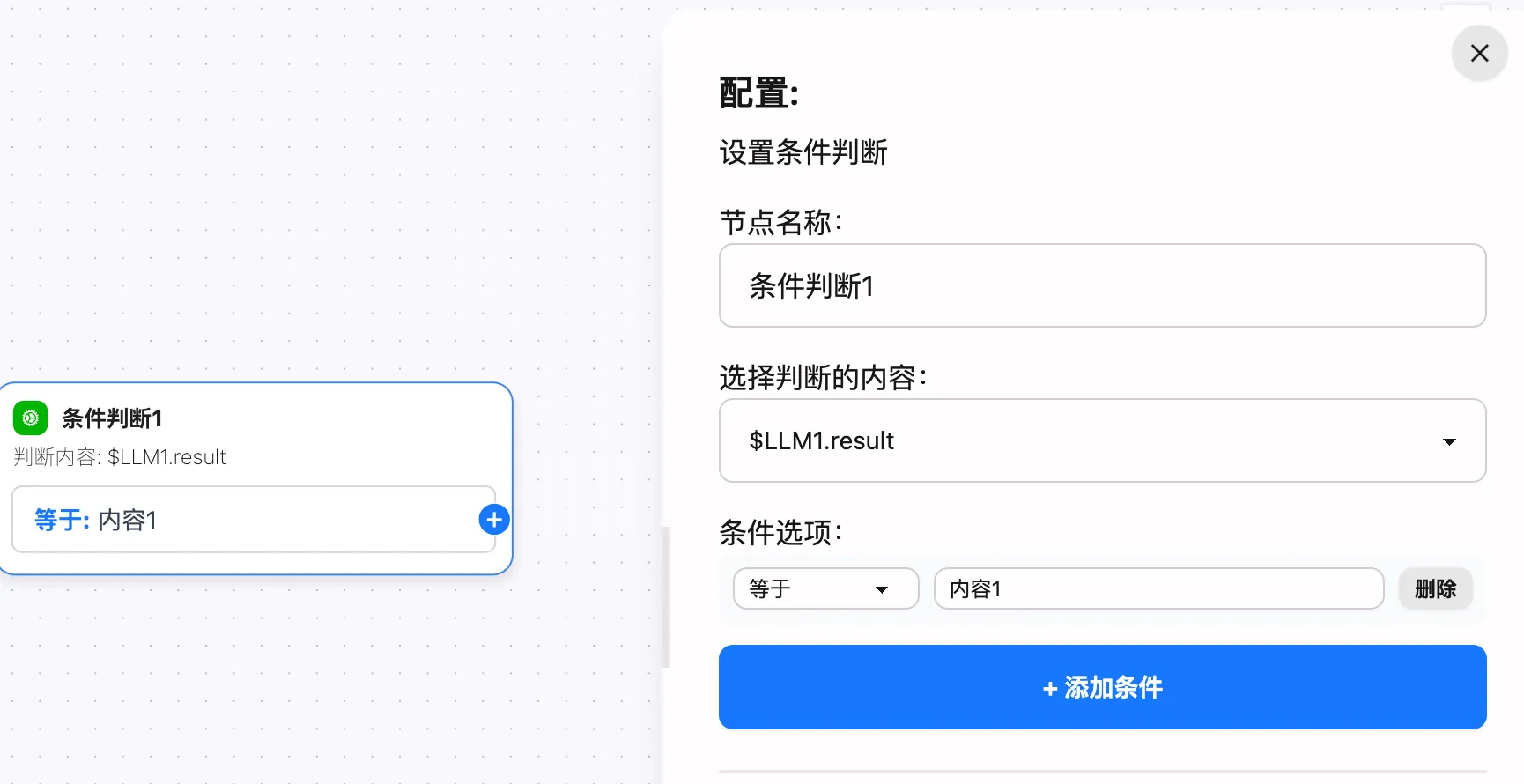
也可以使用條件判斷節點,當 $LLM1.result 包含特定內容時,觸發下一個節點,例如:
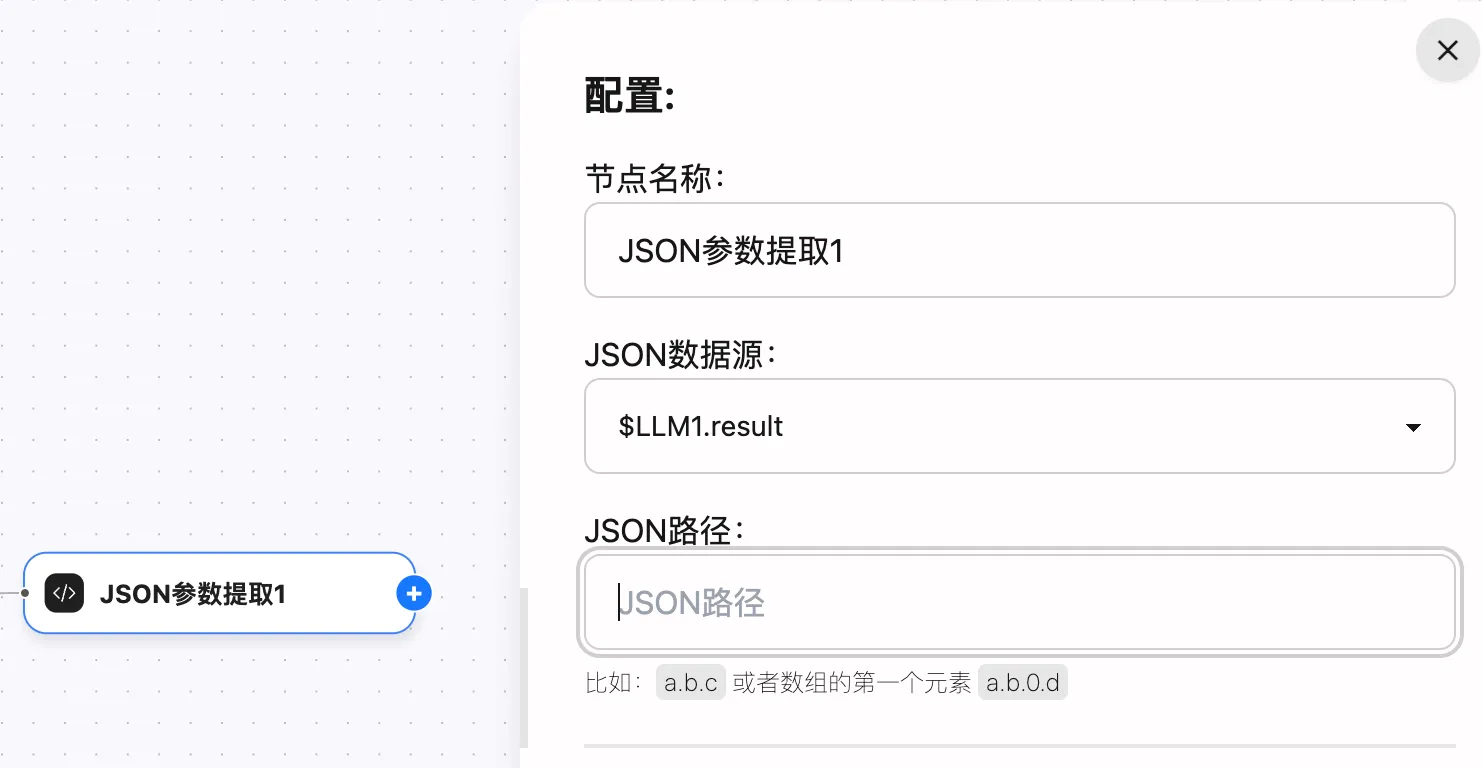
也可以使用JSON,數據處理節點,將 $LLM1.result 的JSON輸出解析後使用,例如:
常見應用場景
- 智能客服對話系統
- 文本內容分析與處理
- 自動化內容生成
- 多語言翻譯與本地化
使用建議與最佳實踐
-
提示詞優化:
- 使用清晰、具體的指令
- 提供充分的上下文信息
- 適當使用示例說明期望輸出
- 分步驟描述複雜任務
-
性能優化:
- 合理設置最大輸出長度
- 必要時啟用JSON輸出
- 避免冗長的提示詞
- 及時清理無用的中間結果
-
調試技巧:
- 先用簡單提示詞測試
- 逐步添加複雜需求
- 保存成功的提示詞模板
- 記錄常見問題和解決方案
-
高級應用:
- 鏈式推理:將複雜任務分解為多個步驟
- 結果驗證:添加輸出質量檢查
- 錯誤處理:預設異常情況的處理方案
- 動態提示詞:根據上下文調整提示策略
通過合理配置和使用LLM節點,您可以充分發揮大語言模型的能力,為您的工作流程添加智能化處理能力。更多關於變量語法的詳細信息,請參閱變量語法指南。
定製服務
官方團隊為您量身定製專業的自動化解決方案