文本截断节点
文本截断节点用于将长文本裁剪为指定长度,支持按照字符或按照行进行截断。当需要限制模型回复、日志内容或展示摘要时,它能在流程中发挥重要作用。
节点配置
基础设置
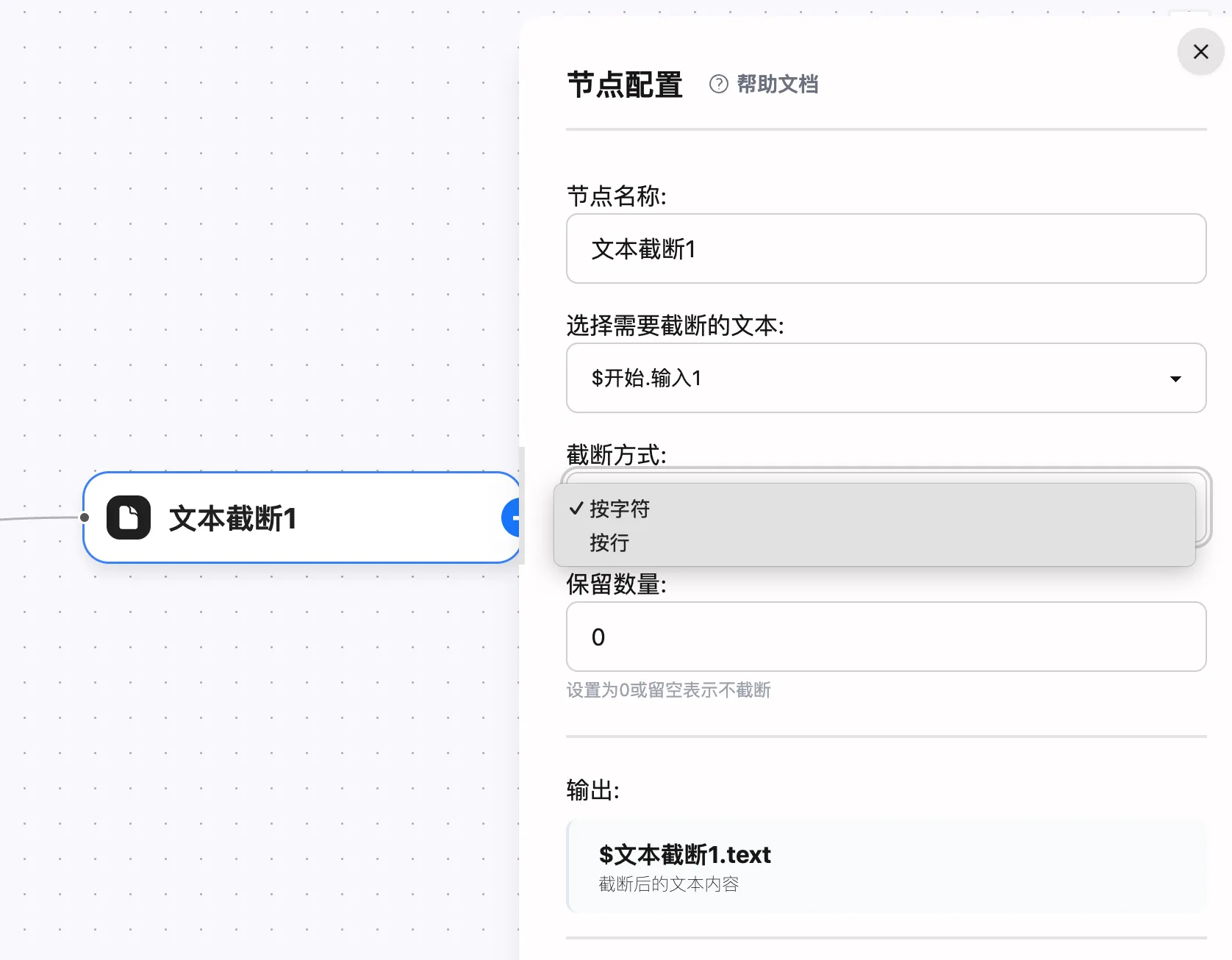
-
节点名称
- 建议使用“动作 + 对象”的命名方式,如“截断AI回复”
- 输出变量默认以节点名称作为前缀,例如
$截断AI回复.text
-
文本来源
- 选择来自上游节点的文本变量,例如
$LLM.output、$输入.content - 支持通过上下文变量引用任意字符串
- 选择来自上游节点的文本变量,例如
-
截断方式
- 按字符(默认):基于 Unicode 字符数量裁剪,适合控制总长度
- 按行:以换行符
\n分割后截取前 N 行,适合日志、表格类内容
-
保留数量
- 填入正整数或 0
- 当值为 0 时,输出为空字符串
- 字段必须填写且为非负数,支持上下文变量替换(例如
$设置.limit)
-
输出变量
- 默认输出键为
text - 在后续节点中通过
$节点名称.text引用截断结果
- 默认输出键为
工作原理
- 节点执行时,会先解析所有输入字段中的
$节点.字段占位符,支持嵌套路径。 - 若“保留数量”为空或非数字,系统会抛出错误,终止当前工作流,以避免不明确的输出。
- 截断逻辑如下:
- 按字符:会按照 Unicode 字符数量裁剪,支持emoji、中文等多字节字符。
- 按行:使用换行符
\n分割,仅截取前 N 行并保持原有换行。
- 截断完成后,节点会把结果写入上下文,可在调试中查看
$节点名称.text。
使用示例
1. 控制模型回复长度(按字符)
- 在 LLM 节点之后添加“文本截断”节点。
- 配置:
文本:$LLM.output截断方式:按字符保留数量:280
- 将
$文本截断.text传递给内容拼接器或输出节点,即可确保回复不超过 280 个字符。
2. 提取日志前几行(按行)
- 输入节点或 HTTP 节点获取多行日志。
- 配置文本截断节点:
文本:$日志抓取.response截断方式:按行保留数量:5
- 在输出节点中引用
$文本截断.text,仅呈现日志的前 5 行。
高级用法
- 动态限制:通过变量控制保留数量,例如
$配置.maxChars,实现按环境动态调整限制。 - 串联使用:先按行截断,再按字符精修,确保文本既保留结构又满足最终长度需求。
- 错误兜底: 在截断后结合条件节点,当输出为空时给出默认提示,避免下游节点收到空内容。
最佳实践
- 事先评估长度:使用内容拼接器或调试功能,确认原始文本长度与期望值的关系。
- 明确单位:团队协作时注明是“按字符”还是“按行”,防止误解。
- 合理拆分:极长文本推荐先使用其他节点(如 JSON 处理或代码执行)预处理,再进行截断。
- 保持幂等:对于可能重复执行的流程,确保截断后的结果可重复使用而不会造成信息丢失。
常见问题
定制服务
官方团队为您量身定制专业的自动化解决方案