Database 数据库节点
Database 节点用于在工作流中直接访问关系型数据库。通过配置连接信息和需要执行的 SQL 语句,你可以在流程中读取业务数据、生成报表、或将AI产出的内容写入数据库,从而让FlowAI与现有系统无缝协作。
节点适用场景
- 数据拉取:查询 CRM、订单、库存等核心系统,为后续分析或提示词提供及时数据。
- 结果回写:将工作流产出的文本、结构化数据写回数据库,形成闭环。
- 自动化巡检:定时执行健康检查或统计语句,结合通知节点推送异常。
- 变量驱动查询:在 SQL 中引用上游节点输出,动态生成查询条件,满足个性化需求。
节点配置
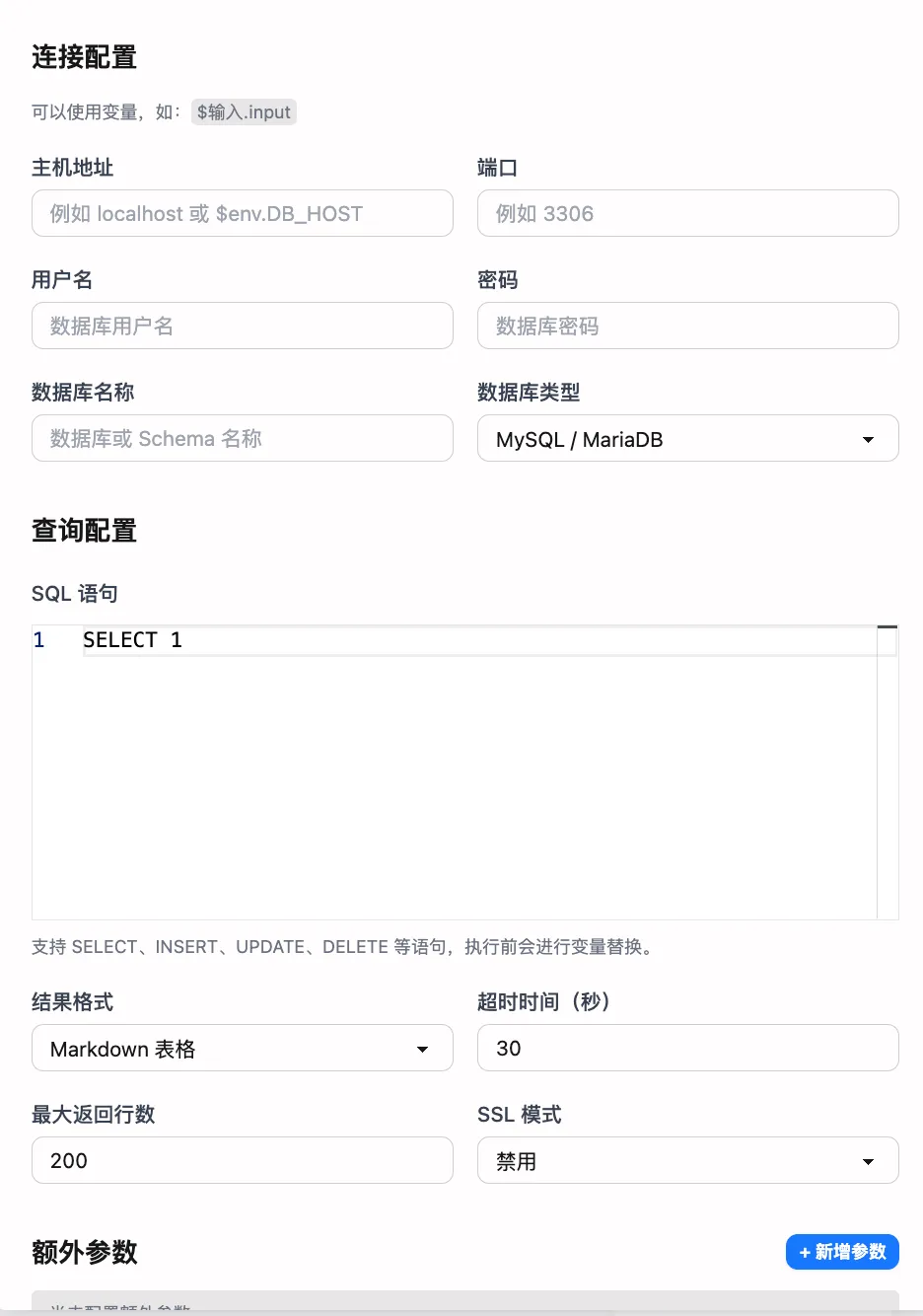
基础连接信息
-
节点名称
- 为节点取一个易于识别的名称,如“查询订单库”或“写入日报”
- 下游节点通过
$节点名称.result引用执行结果
-
数据库类型
- 目前支持
MySQL与PostgreSQL - 根据实际库型选择,系统会自动使用对应的连接方式
- 目前支持
-
主机与端口
host填写数据库地址,可使用内网域名或公网IPport非必填;空置时会使用数据库的默认端口
-
数据库名称与凭证
database指定目标库/Schemausername、password为具备所需权限的账号- 建议创建只读或最小权限账号,避免过度授权
-
变量插值
- 所有输入字段均可使用 FlowAI 变量,例如
$开始.data.host - 节点会先解析变量后再建立连接,方便联动其他节点的输出
- 所有输入字段均可使用 FlowAI 变量,例如
SQL 与输出格式
-
SQL 语句
- 在
sql字段填写需要执行的语句 - 节点会根据语句类型自动识别是“查询”还是“写入/更新”
- 查询语句(如
SELECT、SHOW、WITH等)会返回结果集;其余语句返回受影响行数等信息
- 在
-
结果格式
- 默认以 Markdown 表格形式输出,便于直接展示或发送通知
- 将
format设置为json时,可获得包含columns、rows、truncated信息的结构化结果,适合后续编排使用
-
最大返回行数
max_rows控制查询最多返回的记录数,默认 200 行,上限 5000 行- 超出限制时,节点会截断结果并在输出中标记,避免一次性拉取过多数据
超时与高级选项
-
执行超时
timeout_seconds定义单次执行的最长等待时间,默认 30 秒- 超时会中断执行并返回错误,确保工作流不会长时间阻塞
-
SSL 与其它参数
- 对于 PostgreSQL,可通过
ssl_mode控制连接方式(如disable、require) options支持附加额外的连接参数,使用键值对形式,例如{ "timezone": "Asia/Shanghai" }
- 对于 PostgreSQL,可通过
-
连接可靠性
- 节点会在执行前校验连接可用性,如无法建立连接会立即返回错误
- 建议与循环或条件节点配合,统一处理失败重试逻辑
节点输出
$节点名称.result:当语句执行成功时返回的数据。- 查询语句默认输出 Markdown 表格,或在
json模式下输出{ columns, rows, truncated }结构。 - 写入/更新语句返回包含
rows_affected、可能的last_insert_id等信息的对象或表格。
- 查询语句默认输出 Markdown 表格,或在
$节点名称.error:执行失败时填入错误信息,成功时为空字符串,便于与条件节点联动。
在后续节点中可以通过变量访问执行结果,例如:
最近订单:{{$查询订单库.result}}若采用 JSON 格式输出,下游节点可直接读取 $查询订单库.result 并在节点内部完成解析。
使用示例
示例:读取最新订单数据
-
在 Database 节点中填写:
host: db.internal.localdatabase: salestype: mysqlusername: report_readerpassword: ******sql: SELECT id, customer, total_amount FROM orders ORDER BY created_at DESC LIMIT 10;format: markdown table -
将节点命名为“查询订单库”,后续在通知或LLM节点中插入
$查询订单库.result,即可展示最新订单列表。 -
若需要按日期筛选,可将条件节点输出的日期变量嵌入 SQL,例如
... WHERE created_at >= '{{ $时间节点.result }}'。
示例:写入工作流执行日志
-
将上游生成的总结内容保存到变量
$总结.result。 -
在 Database 节点配置以下语句:
sql: INSERT INTO workflow_logs (workflow_id, summary, created_at)VALUES ({{ $流程信息.id }}, '{{ $总结.result }}', NOW());format: json -
执行完成后,查看
$写入日志.result返回的内容以确认写入是否成功,并结合条件节点触发后续动作。
最佳实践
- 划分账号权限:使用专门的读写账户,限制到所需的库与表。
- 控制数据量:合理设置
max_rows,必要时在 SQL 中增加LIMIT。 - 监控错误:在下游增加条件或通知节点,及时处理
$节点名称.error。 - 结合缓存:对于频繁查询的数据,可搭配变量节点或JSON处理节点缓存结果。
- 记录超时:若经常遇到超时,建议优化 SQL 或在数据库侧使用索引。
定制服务
官方团队为您量身定制专业的自动化解决方案