Web Scraper Node
The Web Scraper Node enables efficient extraction of core web content. It intelligently identifies and extracts valuable information while automatically filtering out ads, navigation bars, and other distractions. Ideal for news aggregation, data analysis, and content curation, it significantly enhances workflow efficiency.
Technical Implementation
Powered by Jina AI Reader, our solution provides:
-
Intelligent Recognition
- Precise main content detection
- Automatic ad/navigation filtering
- Clean Markdown conversion
-
Technical Advantages
- Modern web technology support
- Dynamic content handling
- Site-specific optimizations
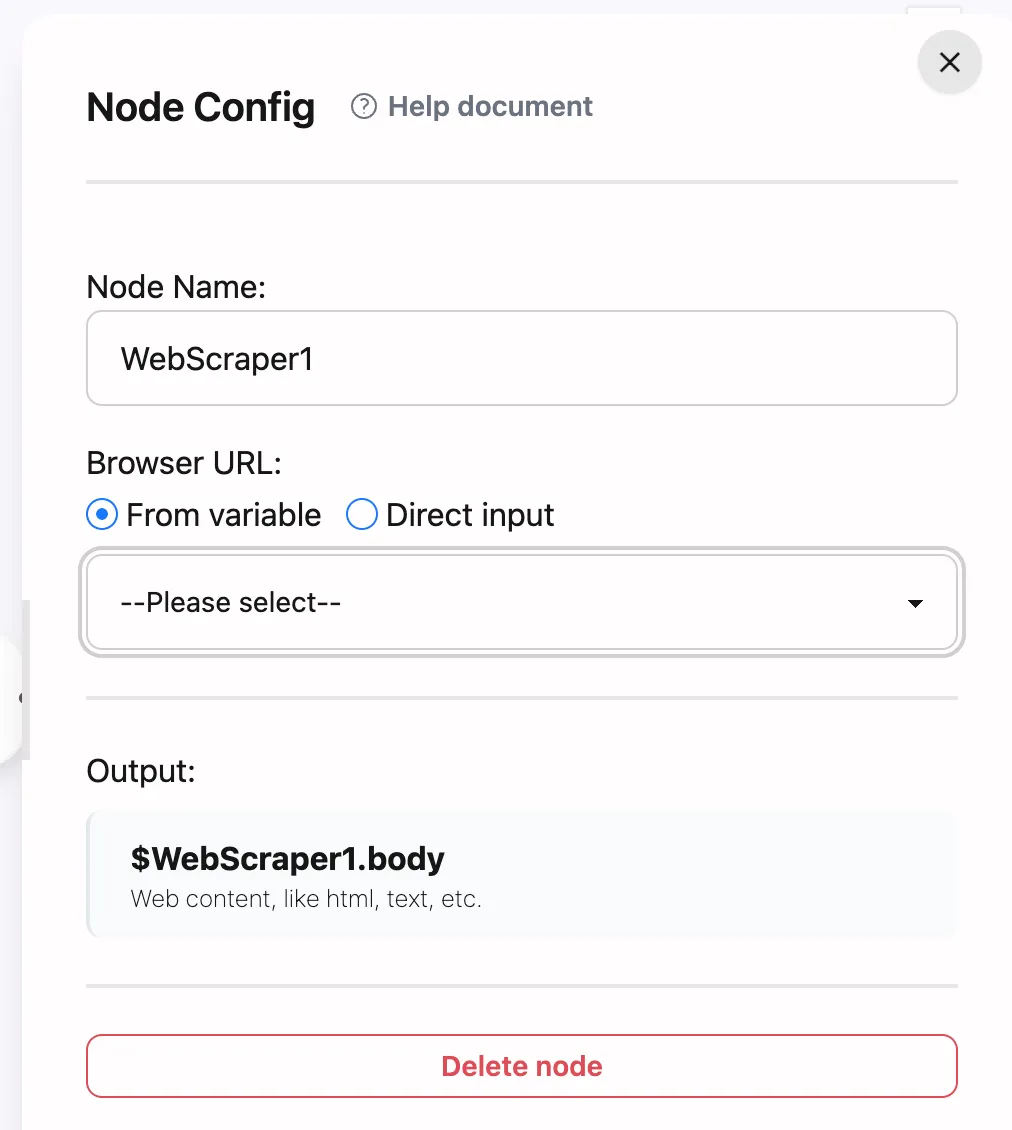
Node Configuration
Basic Settings
-
Node Naming
- Use descriptive names (e.g., “News Scraper”, “Article Collector”)
- Referenced by other nodes using this name
- Update references when renaming
- Maintain naming consistency for easier management
-
URL Input Two input methods:
- Variable Reference
- Dynamic URL sourcing from other nodes
- Specify variable containing URL
- Direct Input
- Manual URL entry
- Include protocol prefix (
http://orhttps://) - Example:
https://example.com/page
- Variable Reference
Output Format
Access outputs via:
$nodeName.body(Markdown formatted)- Preserves essential content structure
- Optimized for downstream processing
Use Cases
LLM-powered News Analysis
[Web Scraper] --------> [LLM Analysis] --------> [Summary Output] | | | Raw Content Insight Extraction Structured SummaryApplications include:
- Automated multi-source news monitoring
- LLM-driven sentiment analysis
- Multilingual summarization
- Knowledge graph construction
- Data visualization integration
Best Practices
URL Handling
- Verify URL format validity
- Encode special characters
- Ensure accessibility
Data Processing
- Combine with LLM for insight extraction
- Use JSON Node for structured data
- Implement regular data backups
Important Notes
Recommended Integrations
-
LLM Node
- Content analysis
- Summary generation
- Multilingual processing
- Sentiment analysis
-
JSON Node
- Data structure parsing
- Field extraction
- Format conversion
- API integration
- Data pipeline construction
Comparison with HTTP Node
While both Web Scraper Node and HTTP Node access web content, they serve different purposes:
Web Scraper Features
- Content-focused extraction
- Automatic noise removal
- Clean Markdown output
- Ideal for content analysis
HTTP Node Features
- Full HTTP request support
- Raw response body access
- Maintains original data format
- Optimized for API integration
Selection Guide
- Use Web Scraper Node for content understanding
- Choose HTTP Node for API interactions
Need a Custom AI Agent?
Custom AI agents designed for real-world business operations.