LLM Node
The LLM node is a core component in FlowAI Smart Workflow for interacting with Large Language Models. Through the LLM node, you can implement various AI application scenarios such as intelligent dialogue, text analysis, and content generation.
LLM Node Basic Configuration
Node Properties Explained
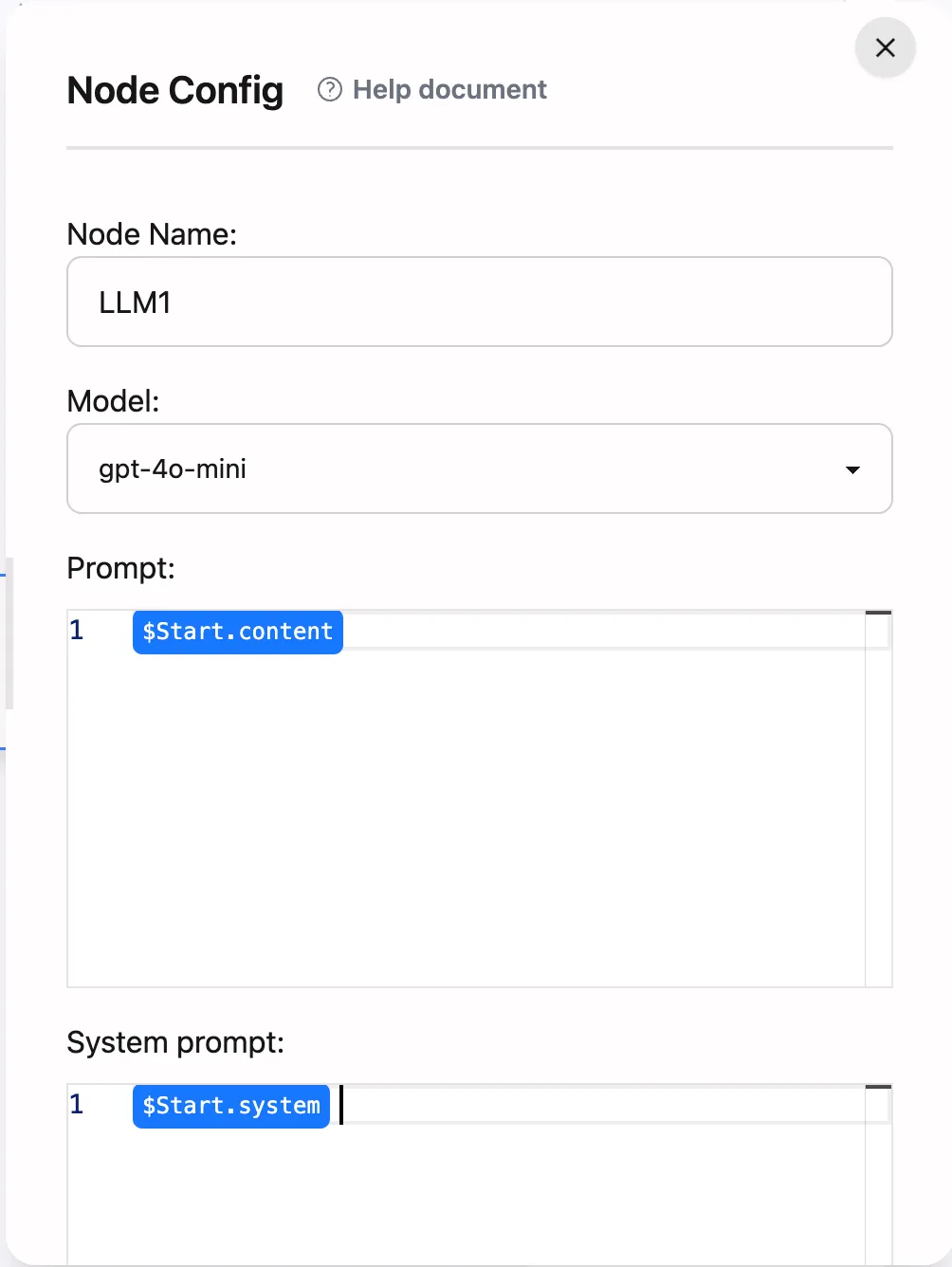
-
Node Name: A customizable LLM node identifier. Modifying it will affect how other nodes in the workflow reference this node. For example, changing “LLM1” to “GPT4” will change references from
$LLM1.resultto$GPT4.result. It’s recommended to use meaningful names for better understanding and maintenance. -
Model: Select the language model to use through the dropdown menu. Currently supports:
- GPT-4o: Good balance between performance and cost
- GPT-4o-mini: Balance between performance and cost
- Other models: Choose based on actual needs
-
Prompt Editing Area: Used to write prompts sent to the language model. You can:
- Use variable syntax to reference outputs from other nodes
- Write multi-line prompts
- Set formatting requirements
-
System Prompt: Used to set the model’s working mode, for example:
- Request model output in JSON format
- Request model output in specific text format
- Request model output with specific topic/style
Model Selection and Comparison
Prompt Writing Tips
Prompts are key to interacting with language models. Good prompts can significantly improve model output quality. Here are some writing tips:
Basic Syntax
I am $start.username, please generate a personalized greeting for me.Structured Output Example
Please analyze the sentiment of the following text and output in JSON format:Text: $input.comment_contentRequired output format:{ "sentiment": "positive/negative/neutral", "confidence": value between 0-1, "keywords": ["keyword1", "keyword2"]}Role Setting Example
You are now a professional copywriter, please help me revise the following text to make it more appealing:$input.original_copyRequirements:1. Keep core information unchanged2. Add emotional elements3. Use more vivid descriptionsAdvanced Configuration Details
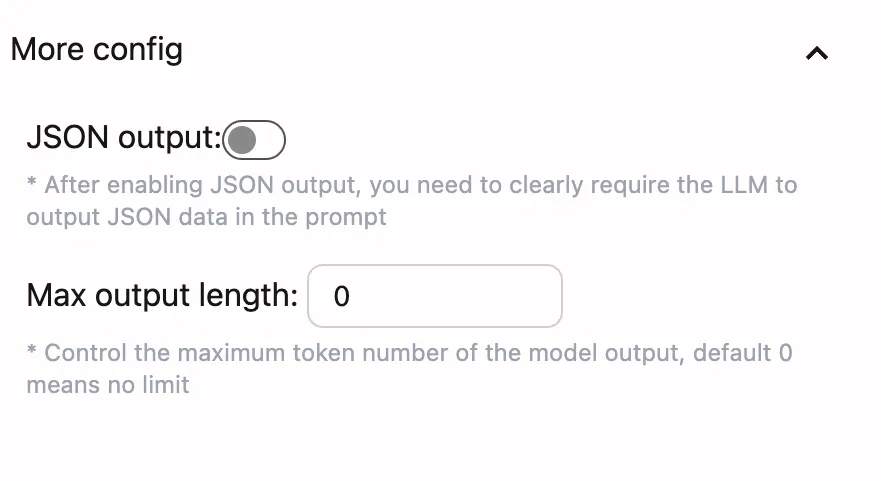
JSON Output Feature
In “More Settings”, you can enable the JSON output feature, which is very useful for scenarios requiring structured data processing:
-
Use Cases:
- Data analysis and processing
- API interface integration
- Multi-turn dialogue state management
- Structured information extraction
-
Best Practices:
- Clearly specify JSON structure in prompts, as the model API will fail if not specified
- Use examples to explain format for each field
- Handle possible exceptions
-
Example Prompt:
Please convert the following text to JSON format:Title: $input.titleContent: $input.contentRequired output format:{ "title": "Article title", "summary": "Summary within 200 characters", "keywords": ["keyword1", "keyword2", "keyword3"], "category": "Article category", "readingTime": "Estimated reading time (minutes)"}Maximum Output Length Control
Setting reasonable maximum output length can optimize performance and cost:
-
Parameter Description:
- 0: No output length limit
- Positive integer: Limit maximum token count
-
Setting Recommendations:
- Short text generation: 500-1000 tokens
- General conversation: 1000-2000 tokens
- Long text generation: 2000-4000 tokens
- Special needs: Adjust based on actual situations
-
Important Notes:
- Token count doesn’t exactly correspond to actual word count
- Chinese characters usually consume more tokens
- Keep sufficient margin to avoid content truncation
Node Output Usage
LLM node output is accessed via $LLMNodeName.result, for example: $LLM1.result
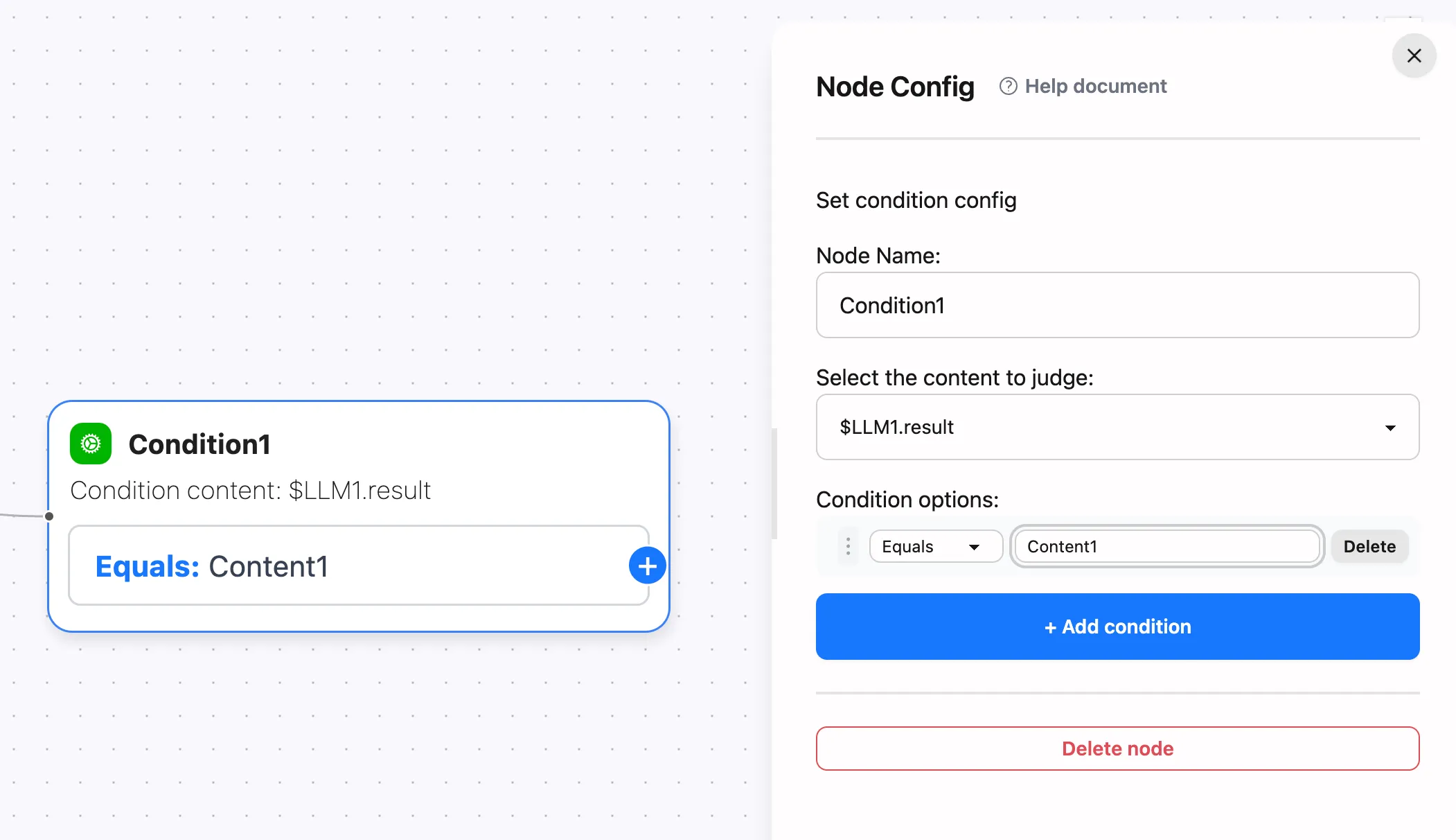
You can also use condition nodes to trigger the next node when $LLM1.result contains specific content, for example:
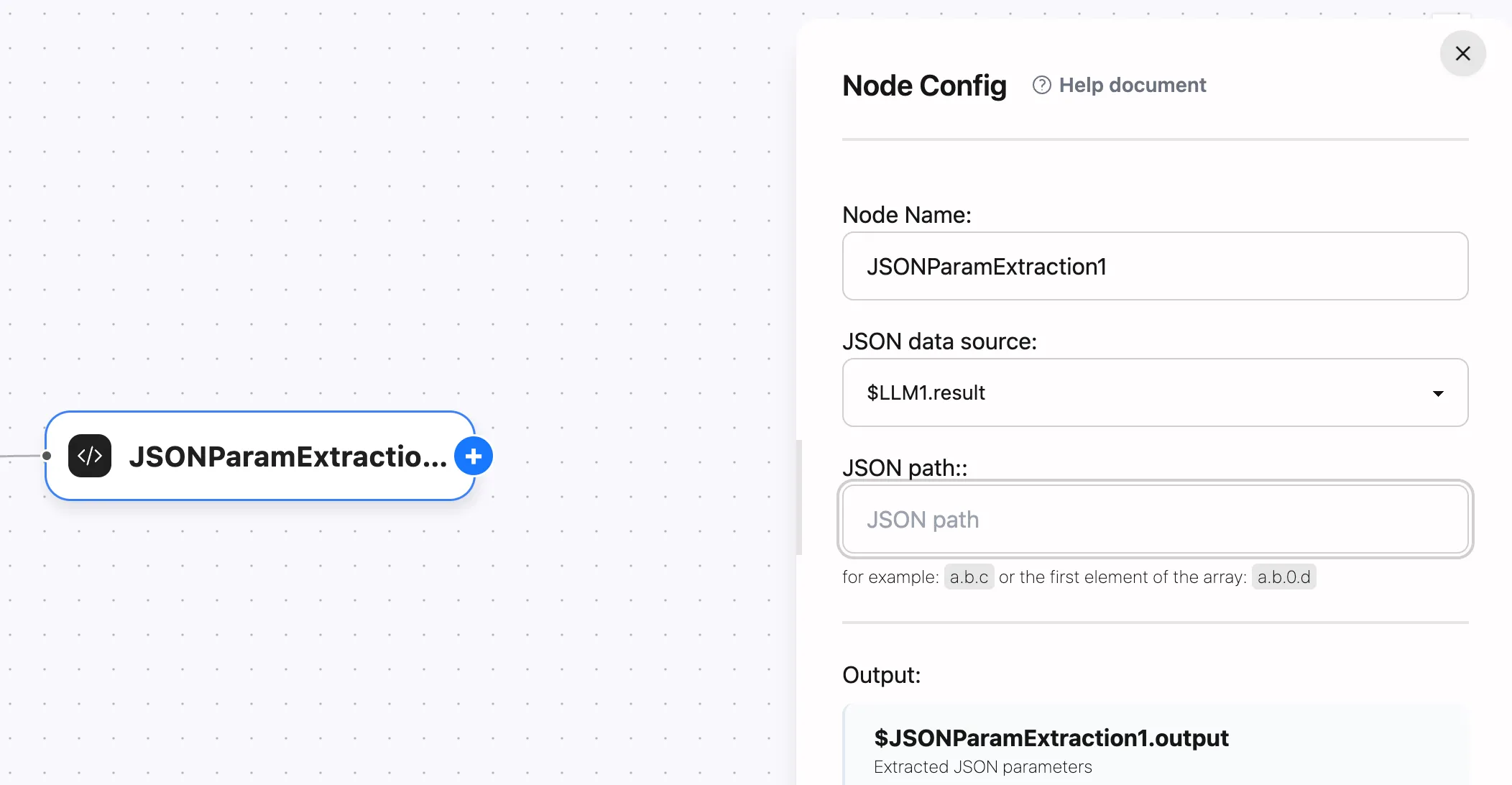
You can also use JSON data processing nodes to parse and use the JSON output from $LLM1.result, for example:
Common Application Scenarios
- Intelligent customer service dialogue systems
- Text content analysis and processing
- Automated content generation
- Multilingual translation and localization
Usage Suggestions and Best Practices
-
Prompt Optimization:
- Use clear, specific instructions
- Provide sufficient context information
- Use examples to explain expected output
- Break down complex tasks into steps
-
Performance Optimization:
- Set reasonable maximum output length
- Enable JSON output when necessary
- Avoid lengthy prompts
- Clean up unused intermediate results
-
Debugging Tips:
- Test with simple prompts first
- Gradually add complex requirements
- Save successful prompt templates
- Document common issues and solutions
-
Advanced Applications:
- Chain reasoning: Break complex tasks into multiple steps
- Result validation: Add output quality checks
- Error handling: Preset solutions for exceptional cases
- Dynamic prompts: Adjust prompt strategy based on context
Through proper configuration and use of LLM nodes, you can fully leverage the capabilities of large language models to add intelligent processing to your workflow. For more detailed information about variable syntax, please refer to the Variable Syntax Guide.
Need a Custom AI Agent?
Custom AI agents designed for real-world business operations.