网页内容抓取节点
网页内容抓取节点能帮你轻松获取网页中的核心内容。它会智能识别并提取有价值的信息,自动过滤广告、导航栏等干扰内容,让你专注于真正需要的部分。无论是新闻采集、数据分析还是内容聚合,都能显著提升工作效率。
技术实现
我们采用了 Jina AI Reader 作为底层服务。这个专业的内容提取平台具备以下能力:
-
智能识别
- 准确定位网页主要内容
- 自动过滤广告、导航等干扰项
- 转换为清晰的Markdown文本
-
技术优势
- 支持现代网页技术
- 处理动态加载内容
- 针对不同网页类型优化
节点配置
基础设置
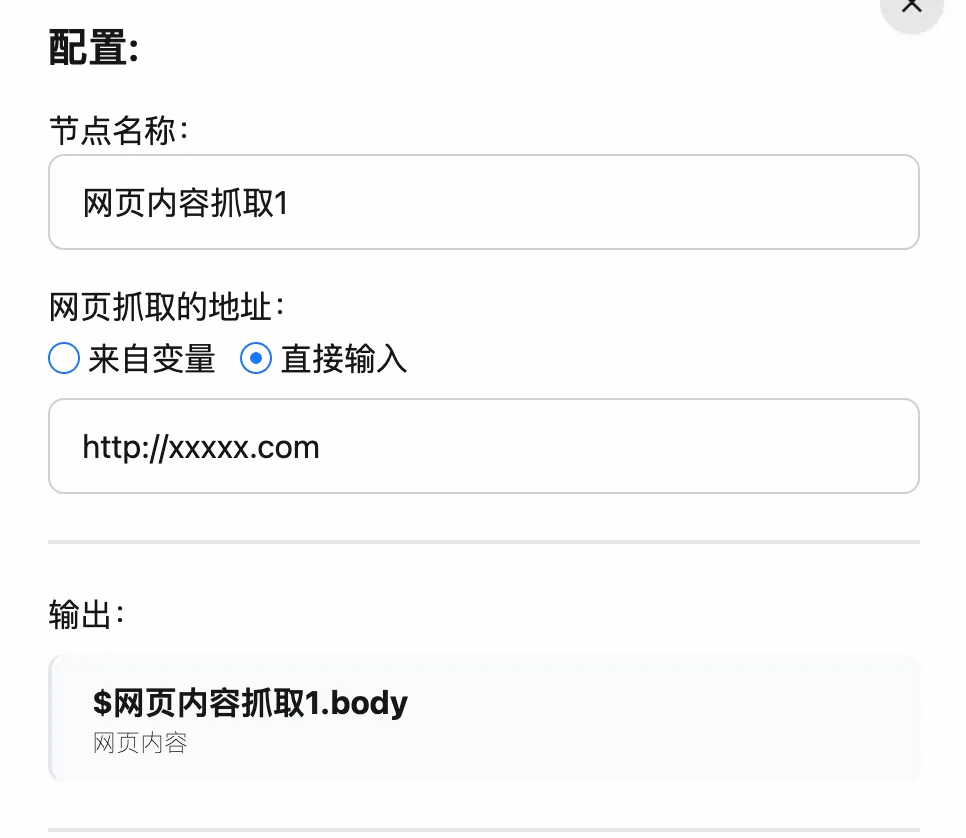
-
节点命名
- 设置一个好记的名字,比如”新闻抓取”、“文章采集”
- 其他节点会用这个名字引用内容
- 改名后引用方式也会相应改变
- 建议用能体现功能的名字,方便后期维护
-
网页地址 两种设置方式:
- 变量引用
- 从其他节点获取网址
- 特别适合动态变化的网址
- 需要指定包含网址的变量
- 直接填写
- 手动输入固定网址
- 记得带上
http://或https:// - 比如:
https://example.com/page
- 变量引用
输出内容
节点会输出以下内容:
- 通过
$节点名称.body获取 - 内容已转为Markdown格式
- 保留了文章的核心信息
- 便于后续处理和分析
实际应用
LLM新闻总结与数据分析
[网页抓取] --------> [LLM分析] --------> [输出摘要] | | | | | | 获取新闻原文 理解内容 输出LLM书写的摘要把它用在新闻总结上,可以:
- 自动抓取多个新闻源,构建新闻监测系统
- 用LLM理解新闻重点,进行情感分析
- 生成简明扼要的摘要,支持多语言
- 提取关键事实和观点,构建知识图谱
- 多维度分析新闻价值,支持数据可视化
使用技巧
网址处理
- 检查网址格式是否完整
- 处理好特殊字符的编码
- 确保网址能正常访问
数据处理
- 配合LLM提取重要信息
- 用JSON节点处理结构化数据
- 及时保存处理结果
注意事项
推荐搭配
这些节点和网页抓取很配:
-
LLM节点
- 分析网页内容
- 生成内容摘要
- 提取关键信息
- 支持多语言处理
- 进行情感分析
-
JSON内容提取
- 解析数据结构
- 提取想要的字段
- 转换数据格式
- 支持API对接
- 构建数据管道
和HTTP节点比较
虽然网页内容抓取节点和HTTP节点都能访问网页,但各有特长:
网页内容抓取节点的特点
- 专门提取有价值的内容
- 自动清理无用的元素
- 输出整洁的Markdown文本
- 特别适合需要理解内容的场景
HTTP节点的特点
- 发送各类HTTP请求
- 获取完整的响应body数据
- 保持原始的数据格式
- 适合API对接场景
怎么选?
- 想读懂网页内容,就用网页内容抓取节点
- 要调用接口拿数据,就用HTTP节点