LLM节点
LLM节点是FlowAI智能工作流中用于与大语言模型进行交互的核心组件。通过LLM节点,您可以实现智能对话、文本分析、内容生成等多样化的AI应用场景。
LLM节点基础配置
节点属性详解
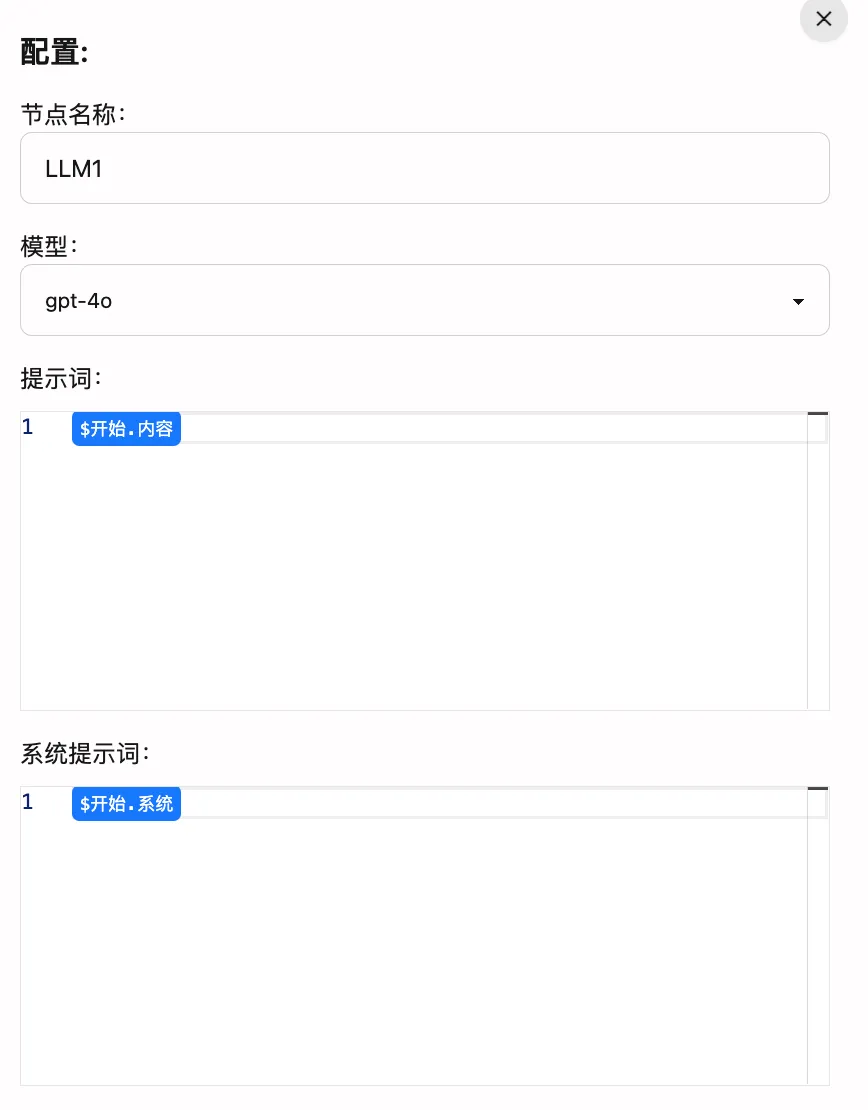
-
节点名称:可自定义的LLM节点标识。修改后会影响工作流中其他节点对该节点的引用。例如,将”LLM1”改为”GPT4”后,其他节点的引用将从
$LLM1.result变为$GPT4.result。建议使用有意义的名称,以便于理解和维护。 -
模型:通过下拉菜单选择要使用的语言模型。目前支持:
- GPT-4o:性能与成本的良好平衡
- GPT-4o-mini:性能与成本的平衡
- 其他模型:根据实际需求选择
-
提示词编辑区:用于编写发送给语言模型的提示词(Prompt)。您可以:
- 使用变量语法引用其他节点的输出
- 编写多行提示词
- 设置格式化要求
-
系统提示词:用于设置模型的工作模式,例如:
- 要求模型输出JSON格式
- 要求模型输出特定格式的文本
- 要求模型输出特定主题/风格的文本
模型选择与对比
提示词编写技巧
提示词是与语言模型交互的关键。好的提示词可以显著提升模型输出的质量。以下是一些编写技巧:
基础语法
我是 $开始.用户名,请为我生成一个个性化的问候语。结构化输出示例
请分析以下文本的情感倾向,并以JSON格式输出:文本:$输入.评论内容要求输出格式:{ "sentiment": "正面/负面/中性", "confidence": 0-1之间的数值, "keywords": ["关键词1", "关键词2"]}角色设定示例
你现在是一位专业的文案编辑,请帮我修改以下文本,使其更加吸引人:$输入.原始文案要求:1. 保持核心信息不变2. 增加感情色彩3. 使用更生动的描述高级配置详解
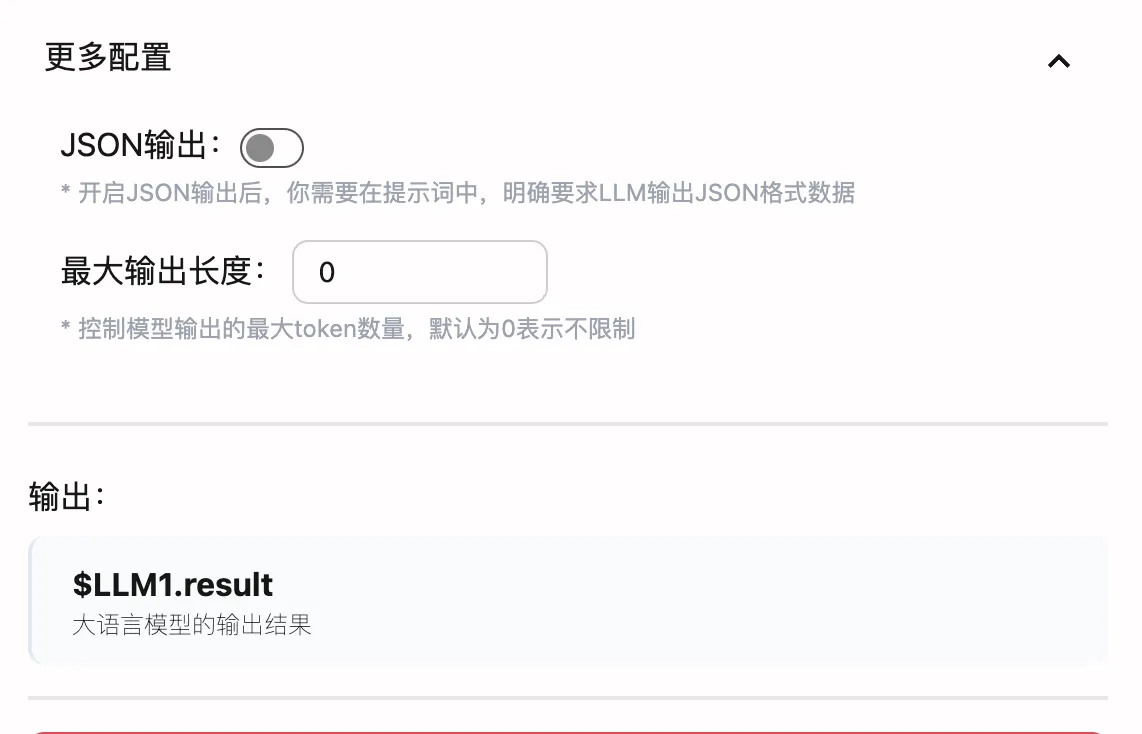
JSON输出功能
在”更多配置”中,您可以启用JSON输出功能,这对于需要结构化数据处理的场景非常有用:
-
使用场景:
- 数据分析和处理
- API接口对接
- 多轮对话状态管理
- 结构化信息提取
-
最佳实践:
- 在提示词中明确指定JSON结构,如果不指定,模型API会返回失败。
- 使用示例说明每个字段的格式
- 处理可能的异常情况
-
示例提示词:
请将以下文本转换为JSON格式:标题:$输入.标题内容:$输入.内容要求输出格式:{ "title": "文章标题", "summary": "200字以内的摘要", "keywords": ["关键词1", "关键词2", "关键词3"], "category": "文章分类", "readingTime": "预计阅读时间(分钟)"}最大输出长度控制
合理设置最大输出长度可以优化性能和成本:
-
参数说明:
- 0:不限制输出长度
- 正整数:限制最大token数量
-
设置建议:
- 短文本生成:500-1000 tokens
- 一般对话:1000-2000 tokens
- 长文本生成:2000-4000 tokens
- 特殊需求:根据实际情况调整
-
注意事项:
- token数量与实际字数不完全对应
- 中文字符通常消耗更多tokens
- 保留足够余量避免内容截断
节点输出使用
LLM节点的输出通过 $LLM节点名称.result 访问,例如: $LLM1.result
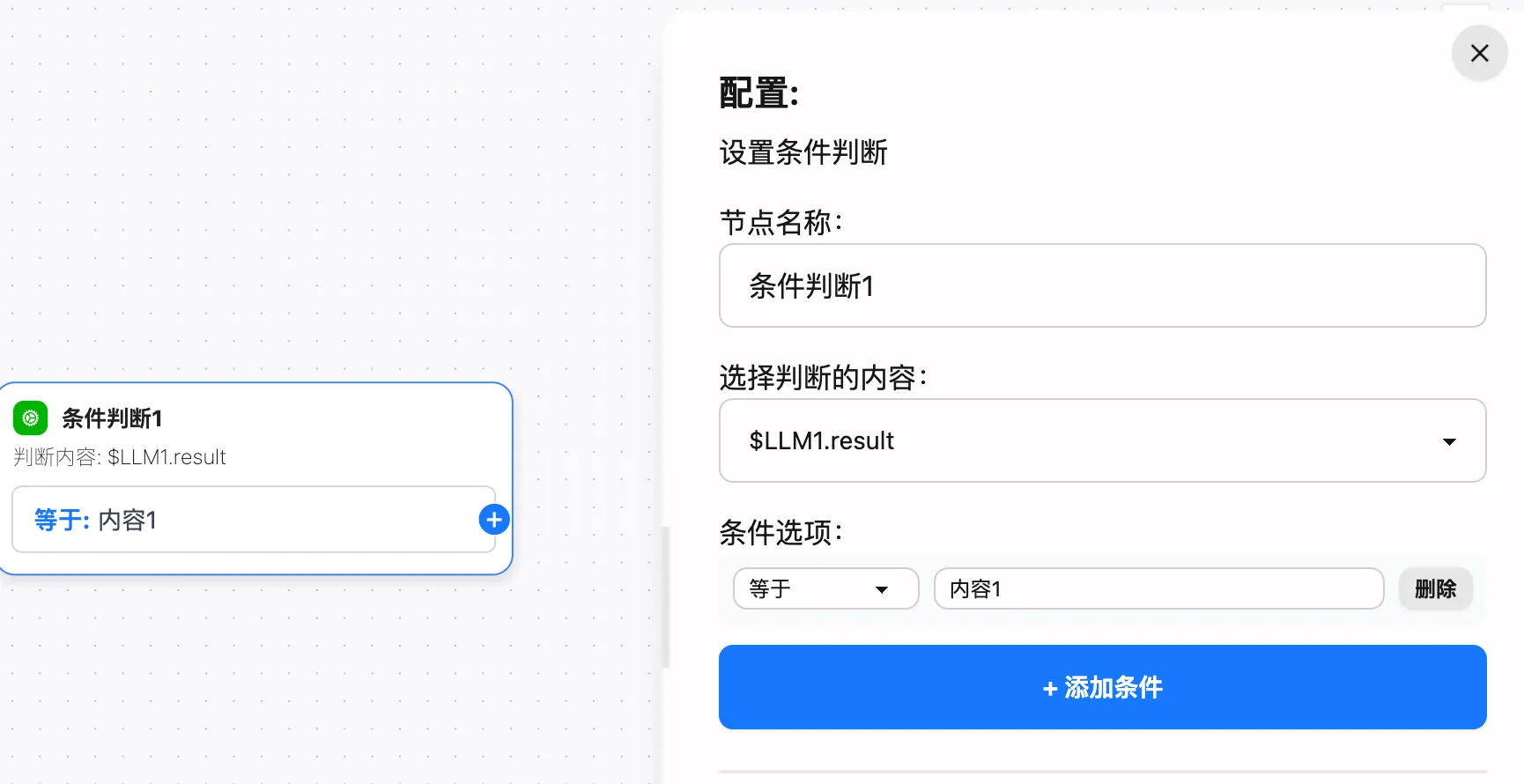
也可以使用条件判断节点,当 $LLM1.result 包含特定内容时,触发下一个节点,例如:
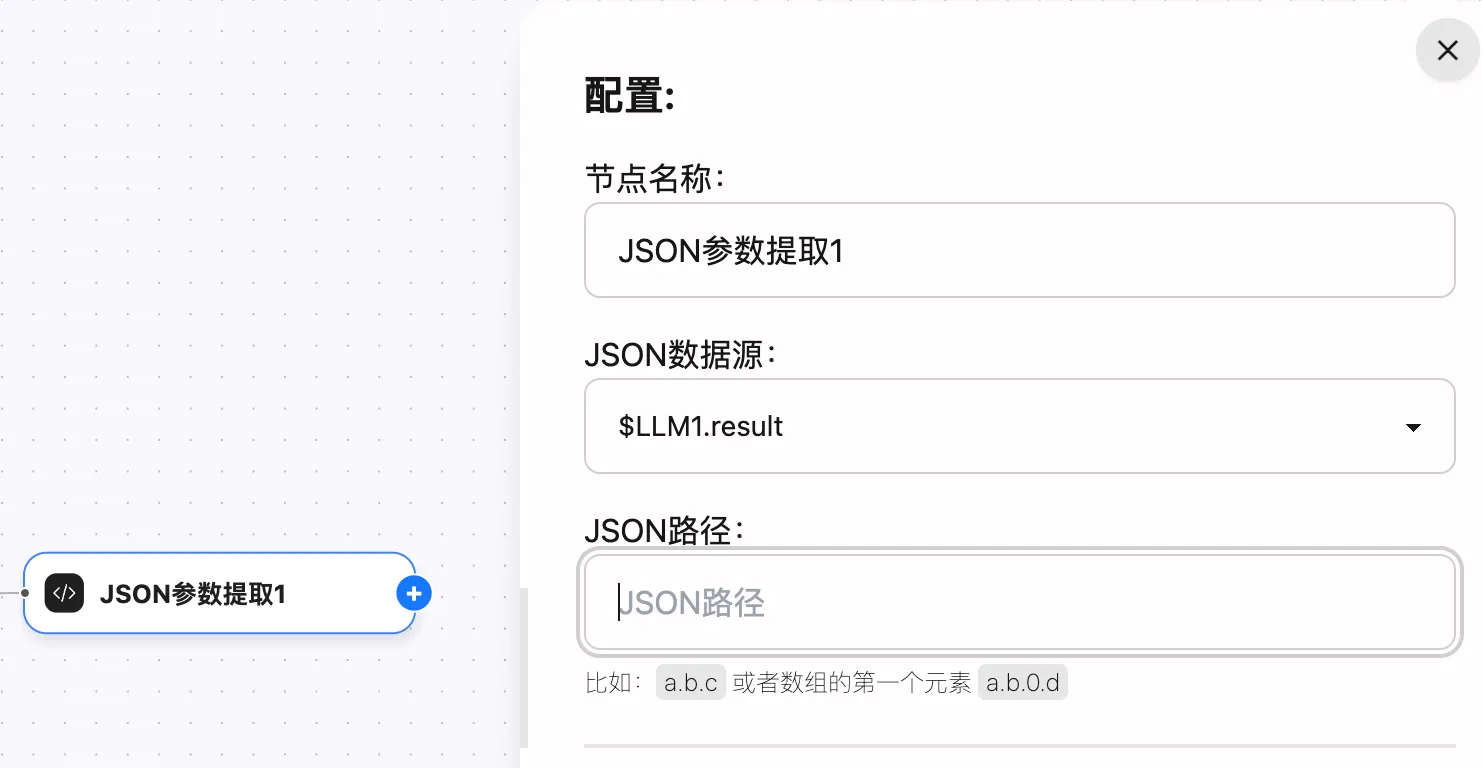
也可以使用JSON,数据处理节点,将 $LLM1.result 的JSON输出解析后使用,例如:
常见应用场景
- 智能客服对话系统
- 文本内容分析与处理
- 自动化内容生成
- 多语言翻译与本地化
使用建议与最佳实践
-
提示词优化:
- 使用清晰、具体的指令
- 提供充分的上下文信息
- 适当使用示例说明期望输出
- 分步骤描述复杂任务
-
性能优化:
- 合理设置最大输出长度
- 必要时启用JSON输出
- 避免冗长的提示词
- 及时清理无用的中间结果
-
调试技巧:
- 先用简单提示词测试
- 逐步添加复杂需求
- 保存成功的提示词模板
- 记录常见问题和解决方案
-
高级应用:
- 链式推理:将复杂任务分解为多个步骤
- 结果验证:添加输出质量检查
- 错误处理:预设异常情况的处理方案
- 动态提示词:根据上下文调整提示策略
通过合理配置和使用LLM节点,您可以充分发挥大语言模型的能力,为您的工作流程添加智能化处理能力。更多关于变量语法的详细信息,请参阅变量语法指南。